

2017년 5월 17일부터 19일까지 개최된 ‘구글 I/O 2017’에서 순다 피차이 구글 CEO는 구글의 다양한 서비스에 인공지능 기술을 결합하는 이른바 ‘AI 퍼스트(AI First)’를 선언했다.
이번 구글 I/O에서 머신 러닝 기술 기반 인공지능 비서인 구글 어시스턴트가 탑재된 구글 렌즈가 가장 주목 받았다. 스마트폰 카메라로 꽃을 찍으면 꽃을 식별하는데 그치지 않고 꽃의 종류까지 파악하며, 거리의 식당의 사진을 찍으면 해당 식당의 리뷰와 지도 팝업 등 각종 정보를 알려주고 더 나아가 예약까지 돕는다. 또 공유기 뒷면의 제품정보를 촬영하면 와이파이(WiFi)가 자동으로 연결된다.
구글 측은 “구글 렌즈를 구글 포토에 우선 적용하고 음성비서인 구글 어시스턴트도 올해 안에 적용해 구글 렌즈를 적극적으로 활용할 것”이라며 기대를 드러냈다.
특히, 향후 인공지능 시장 경쟁이 더욱 치열해질 것으로 전망되는 가운데, 이번 구글 렌즈 공개는 단순히 새로운 서비스 발표 이상의 의미를 가지고 있다. 그동안 구글이 추진하고 있는 방향을 그대로 드러낸 것으로 분석된다. 구글은 인간이 상상할 수 있는 모든 것들을 인공지능을 통해 하나하나 현실화 시키고 있다.
기술이란 인간을 끊임없이 게을러지게 만들고 있는 것이 본질이다. 현재 실리콘벨리에는 마치 SF영화와 같은 신세계에나 나올만한 인공지능 기술들이 개발되고 있다. 즉 상상을 현실화 시키는 기업들이 즐비한데 지금부터 구글 렌즈에 집중해 그간 유사한 서비스를 먼저 개발했거나, 또는 준비한 IT기업들의 사례들을 살펴보자.
마이크로소프트(MS)의 상상, 그리고 애플의 반격
2011년 마이크로소프트가 유튜브에 공개한 ‘Productivity Future Vision 2011(생산성의 미래 2011)’라는 동영상에서 구글 렌즈의 개념이 나온다. 스마트 기기를 사용하는 한 남자가 지하철역 벽면에 설치된 스마트 광고 디스플레이(Display)에 등장하는 한 인물을 카메라로 찍자 해당 인물에 대한 정보를 클라우드를 통해 사용자 스마트기기에 제공한다.
이렇듯 마이크로소프트는 가장 먼저 구글 렌즈와 같은 미래 기술을 상상했지만 아직까지 기술을 개발했거나 시장에 내놓지 못하고 있다. 비단 이뿐만이 아니다. 지금의 태블릿PC 처음 개념(Concept)을 마이크로소프트가 가장 먼저 내 놓았지만 실패했다.
마이크로소프트는 2000년 11월 라스베가스에서 열린 컴덱스(Comdex) 전시회에서 태블릿 PC 프로토타입을 선보였다. 스타일러스 펜과 터치스크린을 탑재해 ‘종이처럼 쓸 수 있는 컴퓨터’를 추구했지만 필기 기능이나 음성인식 기술이 충분히 뒷받침해주지 않아 실패했다. 이어 2003년에는 Windows CE .NET을 탑재해 웹서핑이 가능한 포터블(Portable) 미라(Mira)를 발표했지만 기술환경과 시장환경이 뒷받침해주지 않아 또 실패했다.
하지만 애플은 마이크로소프트가 실패한 제품을 리엔지니어링 과정을 통해 2010년에 9.7인치의 아이패드(iPad)라는 그 유명한 제품을 출시하며 시장을 선점했다. 2013년에는 아이패드의 성공을 바탕으로 두께 7.5밀리 5세대 제품인 아이패드 에어(iPad Air) 출시를 시작으로 지금까지 태블릿PC하면 아이패드를 가장 먼저 떠올릴 만큼 전 세계 시장을 이끌어 가고 있다.
물론 애플도 1983년에 태블릿 프로토타입을 구상하고 1987년에 사용자와 기기가 음성 명령을 통해 상호작용하는 ‘놀리지 내비게이터(Knowledge Navigator)’, 1993년에는 펜과 터치스크린을 탑재한 ‘뉴턴 메시지패드(Newton MessagePad)’라고 불리는 태블릿 PC 개념을 발표했지만 오늘날의 태블릿이라기보다는 PDA에 가까운 형태였다. 또한 태블릿의 원조격으로 불리는 제품들로는 1993년 미국 통신사가 출시한 'AT & T EQ 퍼스널 커뮤니케이터'을 비롯해 2002년 IBM의 메타패드(Meta Pad), 2002년 LG전자가 주문자상표부착생산(OEM) 방식으로 생산한 HP의 ‘TC-1100’ 등이 있었다.
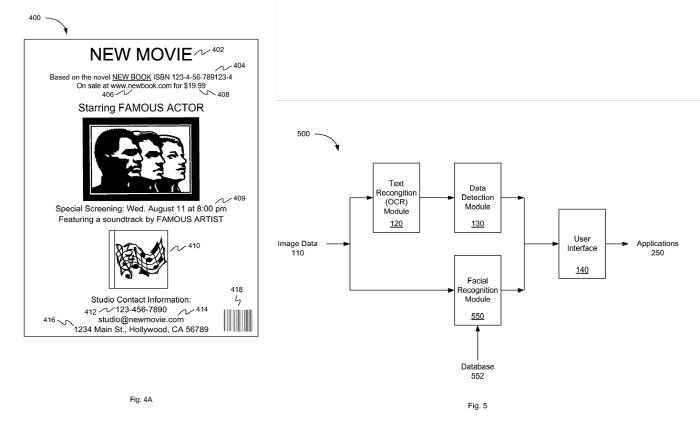
▲ 출처: USPTO
애플(Apple)의 상상과 특허
애플도 이미 2012년에 구글렌즈와 같은 맥락의 특허를 받았다. 애플의 특허 <Integrated Image Detection and Contextual Commands(20120083294, 5 Apr 2012)>는 사용자에게 언제 어디서나 자기가 구매, 인물정보, 책 정보, 영화정보 등을 손쉽게 얻을 수 있도록 해 주는 것으로 CA란 사용자와 주변의 환경을 인식하고 지식을 도출해 정보를 제공한다.
특허 내용을 살펴보면, 차세대 아이 사이트 카메라(iSight Camera)에 텍스트 인식 기술인 OCR(optical character recognition)과 바코드 리더/스캐너, 기타 텍스트의 패턴과 얼굴을 감지하는 기술(pattern detection technologies)까지 융합된다. 따라서 벽이나 전시장에 붙어 있는 각종 전시물, 광고홍보물, 영화 포스터, 또는 영상 등을 아이사이트(iSight) 카메라로 촬영하면, 동시에 홍보물에 붙어 있던 QR 코드나 바코드도 함께 찍힌다. 그 다음 iOS 카메라에 내장된 스캐너가 사진을 스캔하고, 사진에 있는 텍스트나 얼굴 등 정보들을 OCR 모듈과 얼굴인식 모듈(FR Module)을 통해 분석해, 최종적으로 문맥의 패턴과 얼굴이 누구인지를 찾아낸다.
예들 들어 영화 포스터인 경우 문맥 패턴이란 ‘영화 타이틀(movie title)’, 어떤 소설을 바탕으로 만들어진 것인지 그 책의 ‘ISBN 번호’, ‘URL 주소’, ‘가격’, ‘영화상영 날짜와 시간’, ‘전화번호’, ‘이메일주소’, ‘거리주소’, ‘바코드정보’, ‘QR정보’, ‘포스터에 붙어 있는 얼굴’ 등을 말한다. 이러한 정보들을 데이터 감지모듈(Data detection module)을 통해 사용자에게 즉시 문맥 명령메뉴(Context Command Menu0를 보여준다. “웹 사이트를 열까요?”, “전화를 걸까요?”, “이메일을 보낼까요?”, “주소록에 첨가할까요?”, “검색 할까요?”, “티켓을 구매 할까요”” 등등의 Context Menu UI를 통해 사용자에게 커다란 혜택을 주는 획기적인 서비스다.
이는 기존의 명함(Business card)을 관리해주는 앱을 명함보다 수천 배 큰 포스터에 적용해 내용을 관리해주는 아이 사이트(iSight) 시스템과 관련 애플리케이션이다.
기술적인 측면으로 살펴보자. 텍스트 인식 모듈(text recognition module)은 이미지에 있는 중요정보를 이미지 데이터 프로세싱을 거쳐 추출하는데, 여기에는 OCR(optical character recognition)이 사용된다. 얼굴인식 모듈(facial recognition module)은 이미지를 스캔하고 이미지의 얼굴이 누구인지를 찾아내는데, 얼굴의 특징들인, 상대적 위치(position), 크기, 눈, 코, 턱뼈, 턱의 크기를 기존에 알려진 데이터와 비교해 추출한다. 이때 데이터는 디바이스에 있을 수도 있고, 클라우드와 인터넷에 있을 수도 있다.
이때 얼굴인식 알고리즘(facial recognition algorithms)은 두 가지를 사용한다. 하나는 차별화 특징으로 이미지를 보는 기하학(geometric)과 통계적 접근(statistical approach)으로 불일치들(variances)을 제거하는 사진측정(photometric)이다.
다른 스캔 패턴은 다른 상황 별 메뉴를 사용자에게 제공한다. △영화 타이틀과 관련해 ‘극장 위치’, ‘예고편(trailer)’, ‘등급(ratings)’ 등을, △책과 관련해 ‘ISBN’이외에, ‘제목’, ‘저자’, ‘출판사’, ‘인용구(excerpts)’ 등을, △전화와 관련해 ‘SMS로 보내기’, ‘MMS로 보내기’ 등을, △거리주소와 관련해서는 ‘3차원 Map’, ‘찾아가는 방법’ 등을 제공한다.
하지만 애플 역시 2012년 특허 등록 이후로 아직까지 관련 기술이 세상에 나오고 있지 않다. 그동안 애플은 워낙 비밀 프로젝트를 진행하기로 유명하기에 어쩌면 구글 렌즈를 뛰어넘는 준비를 하고 있는지도 모르겠다.
2017년 5월 26일(현지시간) 블룸버그 통신은 애플이 구글 인공지능 기반 프로세서 칩 ‘텐서 프로세싱 유닛(TPU)’와 엔비디아 인공지능 칩과 같은 독자적인 인공지능 전용 칩을 개발 중이라고 전했다.
'애플 뉴럴 엔진'으로 불리는 이 칩은 이미 아이폰 버전을 테스트한 것으로 알려졌으며, 궁극에는 자사의 모든 제품에 탑재해 기능을 향상시킬 것으로 보인다. 그동안 애플 제품에서 인공지능 처리는 메인 프로세서 칩과 그래픽 칩 두 가지를 사용해 처리 했지만, 새로 설계된 전용칩 '뉴럴 엔진' 하나로 작업을 처리할 수 있다.
'애플은 뉴럴 엔진'을 얼굴인식, 음성인식, 자율주행차 소프트웨어, 증강현실, 시리, 아이 클라우드 등에 적용해 인공지능 분야에서 한발 앞서 가고 있다고 평가받는 구글과 아마존을 단숨에 뛰어 넘을 전략으로 보인다.
구글의 상상과 특허, 그리고 현실화:
‘구글, 영상 속 사물인식 특허와 클라우드 비디오 인텔리전스 API 공개’ 인용
구글이 2014년 7월 29일에 ‘자동영상사물인식(Automatic Large Scale Video Object Recognition)’이라는 특허를 미국 특허청에 등록했다. 이는 2012년 8월 28일에 등록한 특허를 개량한 것으로, 청구 항을 43개에서 20개로 줄인 것이다.
영화나 드라마를 보다가 맘에 드는 옷이나 소품을 발견하면, 영상에서 사물에 대한 정보를 받아볼 수 있는 기술이다.
구글이 등록한 특허는 영상에 등장한 사물을 분석해 어떤 사물인지 알려주는 특허로 이름은 ‘자동영상사물인식’이다. 이 특허의 핵심 개념은 ‘특징 벡터(The feature vectors)’로 벡터 기술은 사물이 가진 다양한 특징을 종합해 영상 속 사물이 뭔지 파악하는 기술이다. 색깔이나 움직임, 모양 등이 모두 포함된다. 포괄적인 특징을 한데 엮어 사물을 정의하는 기술이다.
고양이가 나온 동영상에서 구글의 특징 벡터 기술은 고양이의 귀의 특징과 움직임, 체구, 무늬 등을 파악해 영상에 등장한 사물이 ‘고양이’라고 정의한다. 자동차나 사람도 마찬가지다. 네 바퀴가 달린 매끈한 검은색 사물을 자동차로 인식하거나, 두 발로 서 있는 형태를 보고 사람이라고 판단을 내리는 방식이다.
사물이 가진 특징을 뽑아내는 것은 특징 벡터기술이지만, 이 정보를 기초로 최종 판단을 내려주는 것은 서버의 몫으로 고양이의 특징을 서버에 저장된 정보와 매칭시켜야 비로소 고양이라고 분석할 수 있다는 얘기다. 클라우드 서버에 있는 막대한 양의 정보가 사람의 뇌 역할을 하고, 동영상이나 사진이 눈 역할을 하는 셈이다. 따라서 영상에 등장한 사물 정보를 알려주면, 사물을 검색하거나 구매를 유도하는 방향으로 사용자를 이끌 수 있다. 구글의 ‘자동 사물 영상인식’ 기술은 사용자가 영상과 관계있는 다른 행위를 하도록 돕는 역할을 한다.
이어 구글은 2017년 3월 샌프란시스코에서 열린 ‘클라우드 넥스트 2017(Google Cloud Next 2017)에서 영상에 등장하는 사물까지 인식한 뒤 검색 결과로 보여주는 새로운 클라우드 비디오 인텔리전스 API(Google Cloud Video Intelligence API-now in Private Beta)를 공개하고 데모버전을 시연했다.
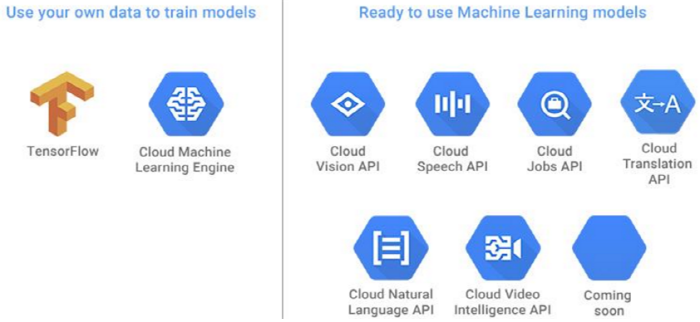
이를 유튜브에 적용하면 영상내용 10억 개의 검색이 가능하다. 앞서 소개한 ‘자동영상사물인식’이라는 특허를 2012년에 등록한지 꼭 5년 만에 이를 비디오에 실제로 적용한 것이다. 따라서 구글의 텐서플로우와 클라우드머신러닝엔진을 이용해 고객들은 이미 발표된 ▲ 클라우드비전API, ▲ 클라우드스피치API, ▲ 클라우드잡스API, ▲ 클라우드번역API, ▲ 클라우드자연언어API에 이어 ▲ 클라우드인탤리전스API를 이용하게 됐다.
고객들은 데모 사이트에서 자신의 동영상이나 구글이 제공하는 컨텐츠를 시험해볼 수 있다. 개발자들은 해당 API의 클로즈베타(CBT) 버전에 접근할 수 있다. 구글은 머신러닝이나 컴퓨터 비전에 대한 배경지식이 없어도 API가 제공하는 비디오 검색 기능의 이점을 누릴 수 있다
이제까지는 사진이나 그림 등 정지된 자료의 물체만을 구분하던 인공지능이 이제는 동영상까지 이해하기 시작한 것이다.
해당 특허를 분석한 차원용 아스펙미래기술경영연구소 대표이자 전 국가과학기술심의회 ICT융합전문위원회 전문위원은 “구글의 특허와 구글의 행보를 바탕으로 검색의 진화 방향을 예측해보면  1세대는 텍스트, 2세대는 이미지, 3세대는 음성 검색, 4세대는 동영상 속의 사물과 인물(2017), 5세대는 촉감(질감), 향기와 냄새와 맛(2020), 6세대는 사람의 감정(2025), 7세대는 사람의 생각/마음(2030)으로 진화할 것으로 보인다”라고 예측하고 있다.
1세대는 텍스트, 2세대는 이미지, 3세대는 음성 검색, 4세대는 동영상 속의 사물과 인물(2017), 5세대는 촉감(질감), 향기와 냄새와 맛(2020), 6세대는 사람의 감정(2025), 7세대는 사람의 생각/마음(2030)으로 진화할 것으로 보인다”라고 예측하고 있다.
구글 렌즈와 카네기멜론대의 합성센서(synthetic sensor):
구글 렌즈에 대해 아주 특이한 관점의 글이 나왔다. 2017년 5월 20일(현지기준) 미국 IT 전문매거진 컴퓨터월드(COMPUTERWORLD)에 IT 칼럼리스트 마이크 엘간(Mike Elgan)의 ‘구글 렌즈, 인공 지능과 슈퍼센서의 부상’이라는 글이 올라왔다.
엘간은 “구글 렌즈는 센서 기술의 미래로 머신러닝으로 인해 센서를 하나만 사용해도 소프트웨어로 100만 개의 다양한 센서를 만들 수 있게 됐다”라며, “구글 렌즈는 소프트웨어 기반의 인공지능 가상 센서들로 구성된 슈퍼센서다”라고 말했다. 이는 구글 렌즈 시연에서 보듯 꽃의 정보를 담은 센서, 코드 리더기, 소매점 식별 도구 등이 필요 없기 때문이다.
또 “4년전만 해도 미래학자들이나 IT업계에서는 사물 인터넷(IoT)에 대해 '조 단위 센서의 세상'(trillion sensor world)라는 개념으로, 모든 제품과 기계에 자신의 정보를 알려주는 각 종 칩이 세상 곳곳에 장착 될 것이라는 상상했었다”라며, “하지만 이들은 인공지능과 머신러닝이 다가오는 미래까지는 생각하지 못했다. 4년의 시간이 흐르는 동안 클라우드 인공지능이 떠오르면서 자동차와 인간, 도로, 기계 등에 전용센서가 아닌 범용 수퍼센서만 필요하다”라고 말했다.
실제로 카네기멜론대(Carnegie Mellon University, CMU) 연구원들은 지난 5월6일 콜로라도 덴버에서 열린 미국 컴퓨터협회(ACM)가 주최하는 '컴퓨터-인간 상호작용 학회(CHI 2017)'에서 ‘합성센서(synthetic sensor)’로도 불리는 '수퍼센서'를 공개했다.
센서들은 두 가지 유형으로 나눌 수 있는데, 하나는 원시센서(raw sensor)이고 다른 하나는 합성센서(synthetic, composite, virtual sensor)다. 원시센서는 주로 광센서, 근접센서, 기압계, 자이로스코프, 습도센서 등이고, 합성센서는 원시센서들의 조합을 소트트웨어로 구현한 센서를 말한다.
카네기멜론대 연구원들은 작업환경에서 주로 사용되는 작은 센서들이 들어있는 상자 형태의 보드를 개발했다. 이 보드는 소리와 진동, 빛, 전자기 활동, 온도 등을 감지해 패턴을 식별하는 데이터가 만들어지고 머신러닝 알고리즘이 이를 처리, '합성센서'를 만들었다.
카네기멜론대 연구원들이 공개한 동영상에는 욕실에서 종이타월을 뽑아 쓰는 기계가 내는 소리를 분석해 사용한 종이타월 수를 계속 파악하며 기록한다. 또한 욕실의 물 사용량도 모니터링 할 수 있다. 즉, 수퍼센서를 한 번 설치하면, 향후 소프트웨어가 어떤 합성센서라도 만들어 낼 수 있다.
결론은 저렴한 센서들을 한 번만 장착하고 연결하면, 이후에는 업그레이드 할 필요없이 소프트웨어로 합성센서들을 만들어 모니터링 할 수 있다. 흥미로운 점은 구글이 이번 카네기멜론 대(CMU) 연구에 가장 많은 자금을 지원했다.
그렇다면, 구글 렌즈와 카네기멜론대의 합성센서 프로젝트는 어디서부터 출발해서 상상을 현실화 시키고 있는 것일까? 눈으로 보고 귀로 들으면 알 수 있는데 왜 항상 만져봐야, 그것도 자세히 알려주고 만져봐야 알지? 라는 질문에서 시작된 인간에 대한 깊은 이해와 상상을 통해 통찰을 얻은 것은 아닐까라는 것이 그리 무리한 생각은 아닐 것이다. "기술에 철학을 담는다는 것, 바로 경쟁력이며 생산성이다."
'자유롭게 > it뉴스' 카테고리의 다른 글
| 소프트뱅크, 산업 사물인터넷 기업 ‘OSI 소프트’에 투자 (0) | 2017.06.15 |
|---|---|
| 올해 웨어러블 기기 시장 점유율 애플워치 압도적 1위 (0) | 2017.06.15 |
| IoT 국제표준화 회의 개최 (0) | 2017.06.14 |
| 소프트뱅크, 산업 사물인터넷 기업 ‘OSI 소프트’에 투자 (0) | 2017.06.14 |
| 4차산업혁명, 빅데이터 분석 및 예측 세미나 개최 (0) | 2017.06.14 |